Chapter 3
Distribute Service
总结分布式服务、互联网技术相关的知识。
总结分布式服务、互联网技术相关的知识。
把后端存储当成一个贯穿很多知识点的 Topic,这样可以把相关的知识点串联起来,形成一个完整的知识体系。
后端存储是分布式服务中最重要的一部分。存储承担了数据的持久化、读写、查询等功能,一个安全可靠、快速稳定的存储基础设施是构建稳定的业务系统的基础。
根据不同的业务场景,选择使用不同的存储技术,是一种能力。
MySQL、Redis、ElasticSearch、HBase、Hive、MongoDB、RocksDB、CockroachDB 等等,这些存储还真就是谁都替代不了谁,每一种都有它擅长的地方,有它适用的场景,当然也有很突出的短板。如何根据业务系统的特点,选择合适的存储来构建我们的系统,是需要学习和掌握的。
目录列表
TODOs
互联网服务中,缓存是提高系统性能的重要手段。缓存的设计需要考虑的因素很多,包括缓存的类型、缓存的位置、缓存的更新策略、缓存的一致性等等。本文将从这些方面来介绍缓存的设计。
缓存,是一种存储数据的组件,它的作用是让对数据的请求更快地返回。实际上,凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存。
技术为业务服务,缓存也不例外;在业务系统中,主要会用到以下几种缓存:
一般也叫 Local Cache, 是指缓存在应用进程内部的缓存,比如 Java 中的 HashMap、ConcurrentHashMap 等。这种缓存的特点是速度快,但是缓存的数据量有限,一般只能缓存一些热点数据;此外,这类缓存会引入多实例下数据短暂不一致的问题,所以在使用的时候要格外小心。
经常使用的 Local cache 有:Google Guava Cache、Caffeine、ConcurrentHashMap、Ehcache 等。目前 Caffeine 是性能最好的 Local Cache。此外,leveldb 也是一种本地缓存的实现,但是它是基于磁盘的,所以性能不如上面几种。
举几个场景
总结一下
Local Cache 和应用服务处于同一个进程内,且存储在内存中,一个字:快;无论对于 RT、QPS 还是吞吐量,都有极大增益。此外,也节省了内网带宽。
依据服务无状态设计的原则:尽量把数据的状态和存储放在专门的数据存储服务中,实例节点本身只做计算,不把数据状态和某个实例做耦合,这样在水平扩展时才能收放自如。本地缓存其实在一定程度上引入了状态,所以一个最需要关心的问题就是数据一致性,这一点有别于分布式缓存。
HashMap、ConcurrentHashMap 等TODO
缓存可以应对高并发大流量的场景。
在做缓存设计时,有一些误区要避开:
找几个例子分析一下
https://bbs.huaweicloud.com/blogs/365239 https://mp.weixin.qq.com/s/36kVm4pfiy2vQEMToZ9--g https://cloud.tencent.com/developer/article/1546995 https://juejin.cn/post/6844903961078530062 https://mp.weixin.qq.com/s/YBpOz1dQ0sG15vGL7N0PeQ https://shniu.gitbook.io/cs/middleware/redis https://shniu.gitbook.io/cs/system-design/backend-store/cache-design https://tech.meituan.com/2017/03/17/cache-about.html http://highscalability.com/blog/2016/1/25/design-of-a-modern-cache.html https://juejin.cn/post/7151937376578142216 https://juejin.cn/column/7140852038258147358
Backend for Frontend 是一种模式,在构建 API 时当然可以不选择使用 BFF,取而代之的是对多个 UI 终端提供一个统一的 API,但是不可避免的会带来一些问题:
总结来看:由于不同终端的差异性,导致对后端 API 的数据产生了不同的需求,驱动我们去考虑针对不同的 UI 来定制不同的接口。
通用的 API 后端和团队组成如下
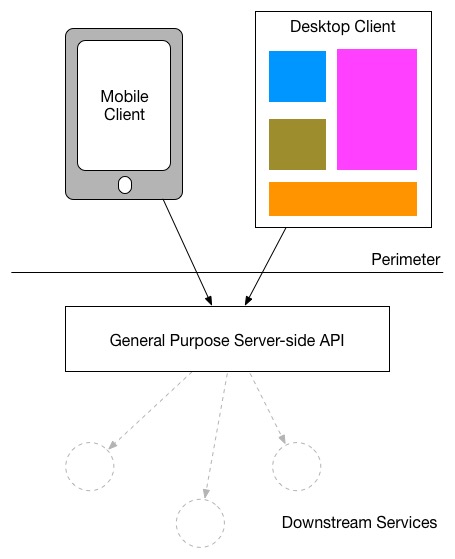
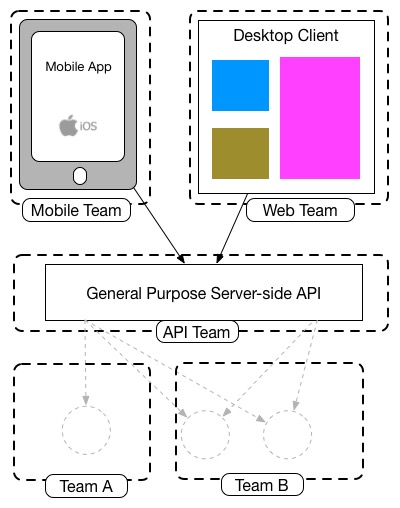
The goal of the BFF pattern is to decouple the front-end applications from the back-end services and to reuse the APIs while ensuring that it doesn’t cause over-fetching or over-requesting on the client-side. This is accomplished by developing a dedicated back-end for each front-end service. The BFF transforms the data into the correct format that the client application needs.
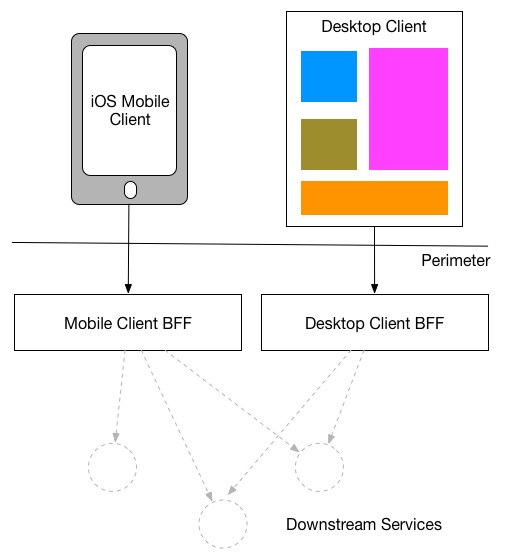
关于 BFF 的实践可以看一下 BFF @ SoundCloud 这篇文章,里面有一些很好的实践经验。
什么时候用 BFF ? 当你有多个微服务,并且需要应对不同的 UI 终端,而且这些终端之间存在差异性,可以考虑使用 BFF 模式。
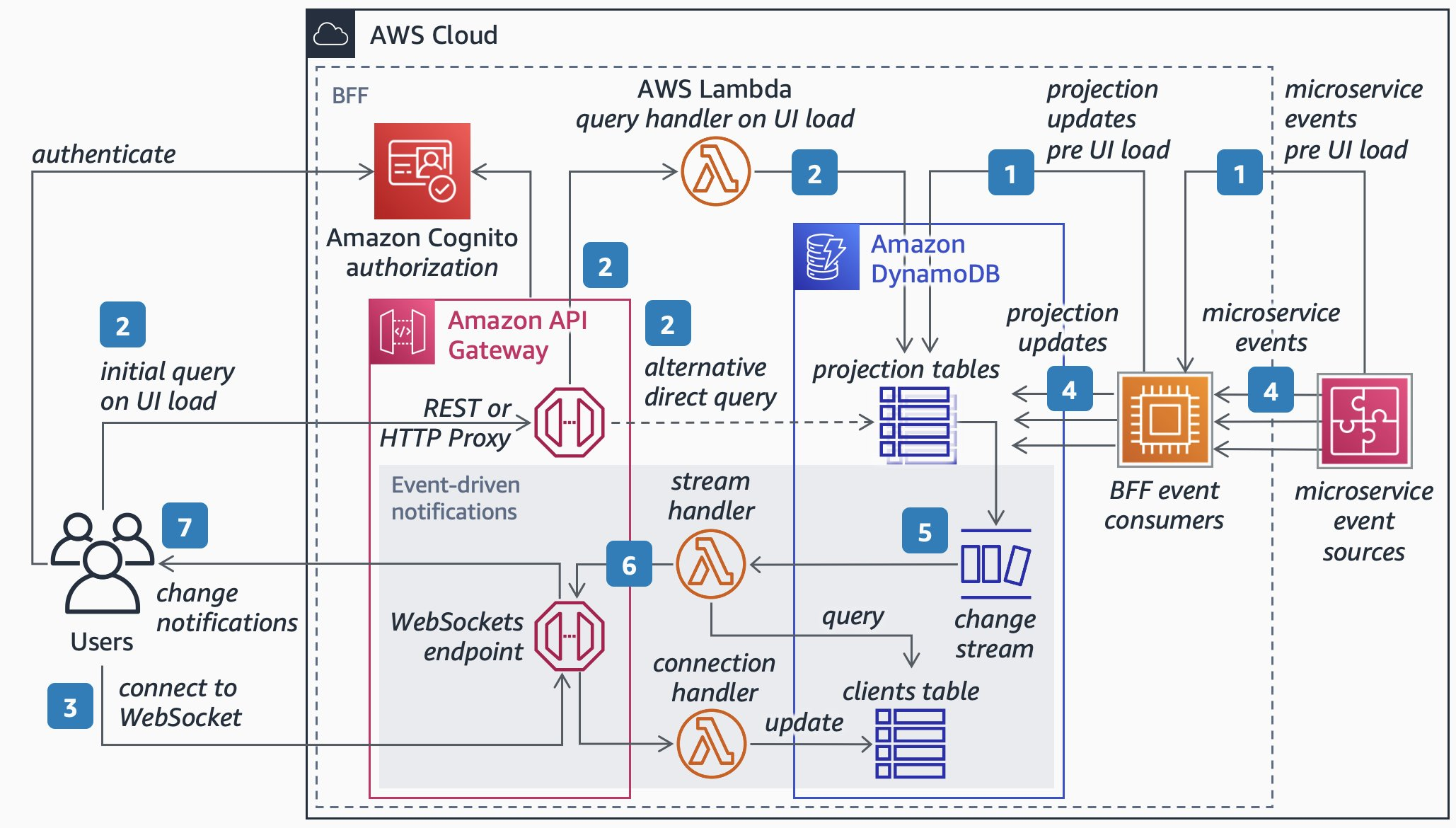
AWS 提出了一个 event-driven BFF 的东西: Backends for Frontends Pattern by AWS
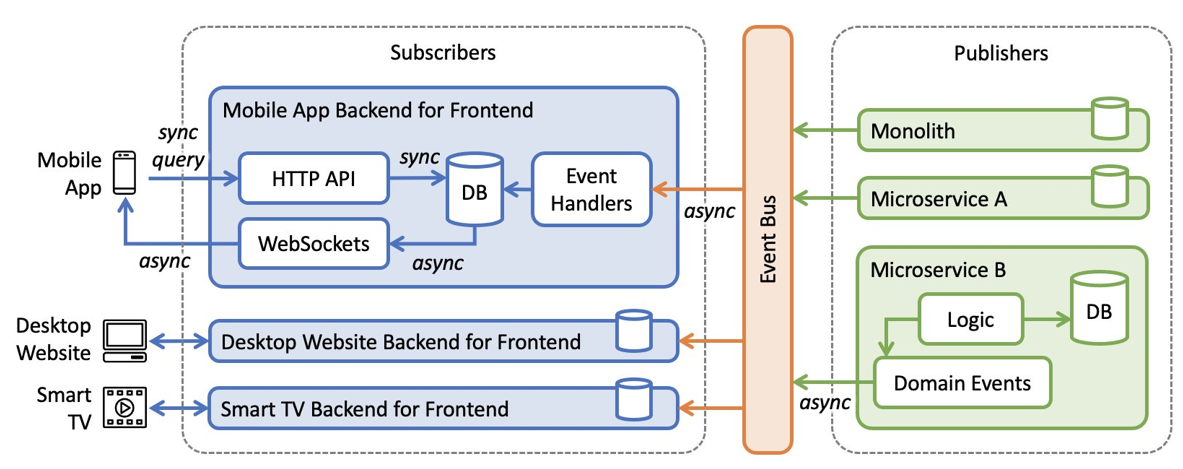
还有一种更加云原生的方式来构建服务